Zaawansowane umiejętności ChatGPT, takie jak rozwiązywanie problemów z kodem, pisanie eseju czy opowiadanie dowcipów, przyczyniły się do jego ogromnej popularności. Pomimo tych zdolności, jego wsparcie było ograniczone do tekstu - ale to się zmieni.
Wtorek OpenAI przedstawił GPT-4, dużo rodzajowy model, który przyjmuje wejścia zarówno w postaci tekstu, jak i obrazu i generuje wyjście w postaci tekstu.
Również: Jak sprawić, aby ChatGPT dostarczał źródeł i cytował
Różnica między GPT-3.5 a GPT-4 będzie "subtelna" w nieformalnej rozmowie. Jednak nowy model będzie o wiele bardziej zdolny pod względem niezawodności, kreatywności i nawet inteligencji.
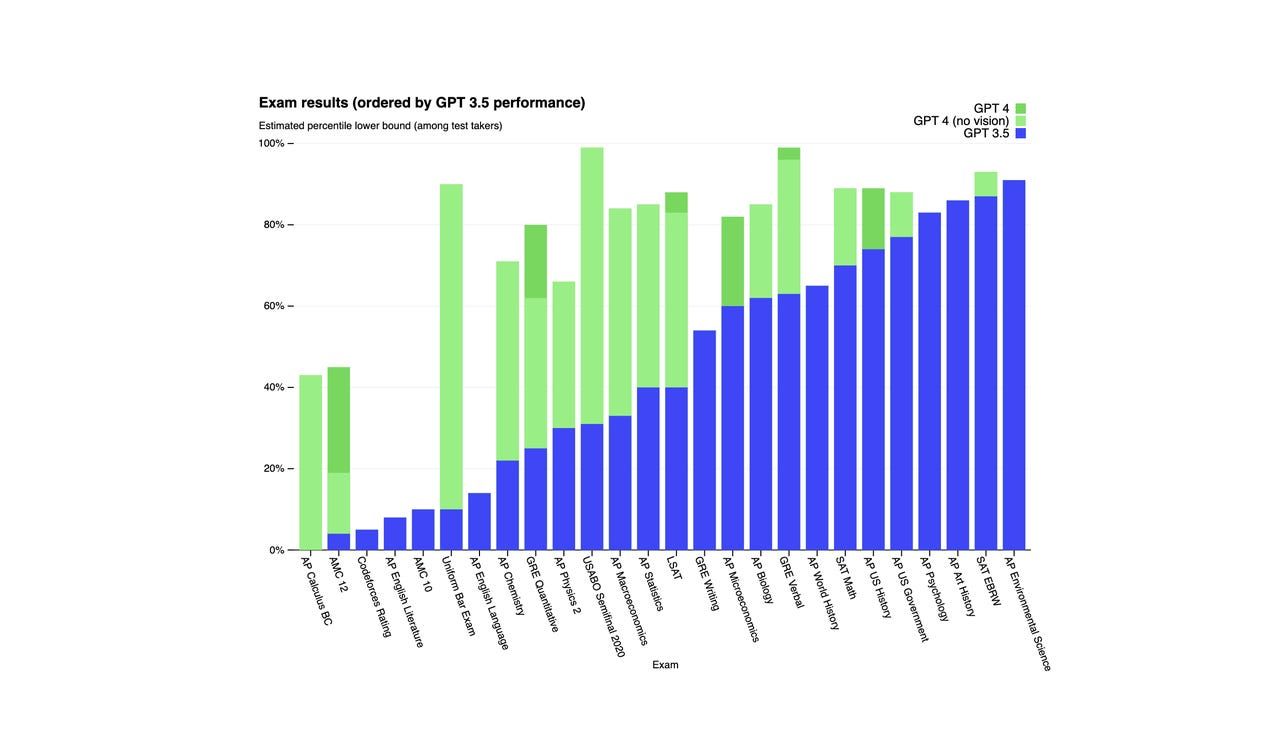
Zgodnie z OpenAI, GPT-4 uzyskał wynik w górnej 10% w symulowanym egzaminie prawniczym, podczas gdy GPT-3.5 uzyskał wynik w dolnej 10%. GPT-4 również okazał się lepszy od GPT-3.5 w serii testów referencyjnych, co widać na poniższym wykresie.

W kontekście, ChatGPT działa na modelu językowym dostrojonym z modelu z serii 3.5, który ogranicza działanie chatbota do generowania tekstu.
Ogłoszenie GPT-4 przez OpenAI nastąpiło po wystąpieniu Andreasa Brauna, CTO Microsoftu w Niemczech, w ubiegłym tygodniu, w którym powiedział, że GPT-4 pojawi się wkrótce i umożliwi generowanie tekstu na wideo.
Także: Jak działa ChatGPT?
"W przyszłym tygodniu przedstawimy GPT-4; tam będziemy mieli modele multimodalne, które będą oferować zupełnie inne możliwości -- na przykład filmy" - powiedział Braun według Heise, niemieckiego dziennika na wydarzeniu.
Pomimo faktu, że GPT-4 jest multimodalny, twierdzenia dotyczące generowania tekstów na podstawie wideo były nieco nietrafione. Model jeszcze nie jest w stanie produkować wideo, ale może przyjmować dane wizualne, co stanowi istotną zmianę w porównaniu do poprzedniego modelu.
Jednym z przykładów, który OpenAI udostępniło aby pokazać tę funkcję, jest prezentacja ChatGPT skanującego obraz w celu zrozumienia, co na zdjęciu jest zabawne, zgodnie z wprowadzonym przez użytkownika.
Inne przykłady obejmują przesyłanie obrazu wykresu i proszenie GPT-4 o wykonanie obliczeń lub przesyłanie arkusza i proszenie go o rozwiązanie pytań.
Także: 5 sposobów, w jakie ChatGPT może pomóc Ci napisać esej
OpenAI informuje, że udostępni funkcjonalność wprowadzania tekstu GPT-4 poprzez ChatGPT oraz API za pośrednictwem listy oczekujących. Na funkcję wprowadzania obrazu będziesz musiał trochę poczekać, ponieważ OpenAI współpracuje z jednym partnerem, aby rozpocząć ten proces.
Jeśli jesteś rozczarowany z powodu braku generatora tekstu na wideo, nie martw się, to nie jest zupełnie nowy pomysł. Giganci technologiczni, tak jak Meta i Google, już pracują nad takimi modelami. Meta ma Make-A-Video, a Google Imagen Video, które oba wykorzystują sztuczną inteligencję do tworzenia wideo na podstawie danych wprowadzanych przez użytkownika.